How Fintech companies use Machine Learning to detect Fraud Detection
Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it. Many researchers also think it is the best way to make progress towards human-level AI.
Why is machine learning important?
The recent hype is driven by three key developments, which have reduced the barrier to entry for organizations across sector and stage that want to apply machine learning:
- More data and cheaper storage: The rise of cloud-based tools and the plummeting cost of storing data through services like Amazon Redshift mean that more data than ever is routinely generated and stored by business-critical applications.
- Open-source libraries: Widely available machine learning libraries like Google’s TensorFlow and Scikit-learn make cutting edge algorithms more accessible to a wider audience of data scientists and generalist software engineers.
- The development of cloud-based platforms and custom hardware optimized for machine learning means that these applications can run faster and at lower cost, increasing their suitability for variety of business needs.
Different machine learning methods:
Two of the most widely adopted machine learning methods are supervised learning and unsupervised learning — but there are also other methods of machine learning. Here’s an overview of the most popular types.
- Supervised learning algorithms are trained using labeled examples, such as an input where the desired output is known. The learning algorithm receives a set of inputs along with the corresponding correct outputs, and the algorithm learns by comparing its actual output with correct outputs to find errors. It then modifies the model accordingly. Supervised learning is commonly used in applications where historical data predicts likely future events. For example, it can anticipate when credit card transactions are likely to be fraudulent or which insurance customer is likely to file a claim.
- Unsupervised learning is used against data that has no historical labels. The algorithm must figure out what is being shown. The goal is to explore the data and find some structure within. Unsupervised learning works well on transactional data. For example, it can identify segments of customers with similar attributes who can then be treated similarly in marketing campaigns. Or it can find the main attributes that separate customer segments from each other.
- Semisupervised learning is used for the same applications as supervised learning. But it uses both labeled and unlabeled data for training.
- Reinforcement learning is often used for robotics, gaming and navigation. With reinforcement learning, the algorithm discovers through trial and error which actions yield the greatest rewards. This type of learning has three primary components: the agent (the learner or decision maker), the environment (everything the agent interacts with) and actions (what the agent can do). The objective is for the agent to choose actions that maximize the expected reward over a given amount of time.
Applications of Machine Learning
- Social Media
- Transportation
- Products Recommendations
- Virtual Personal Assistants
- Self Driving Cars
- Fraud Detection
Security and Fraud Detection Using Machine Learning
The financial sector is a prime target for cyberattacks, with financial institutions (FI) around the world defending against breaches and spending up to $3,000 per employee annually on cybersecurity measures.
These defenses take a variety of forms, ranging from transaction review teams to static rules-based verification measures to biometric authentication processes. Banks are constantly looking for new ways to ensure this annual security budget is spent more efficiently, devoting time and funds toward ever-more-advanced fraud prevention.
Some of the most promising of these innovations are artificial intelligence (AI) and machine learning (ML), which analyze thousands of transactions in real time to look for any anomaly that could be a sign of fraud.
Machines are much better than humans at processing large datasets. They are able to detect and recognize thousands of patterns on a user’s purchasing journey instead of the few captured by creating rules. This is the reason why we use machine learning algorithms for preventing fraud for our clients.
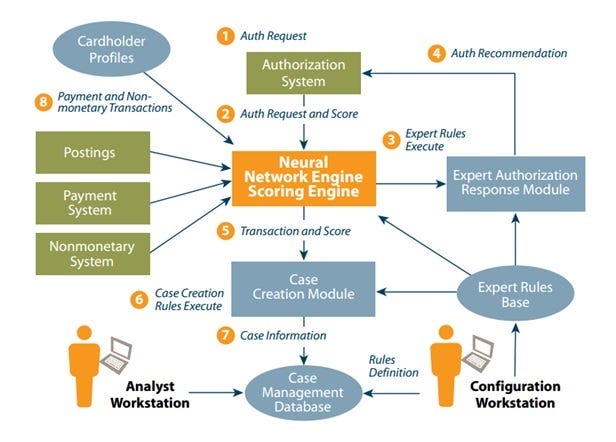
How does a Machine Learning system work for Fraud Detection?

The above picture shows the basic structure of the working of fraud detection algorithms using Machine Learning:
Feeding data: First, the data is fed into the model. The accuracy of the model depends on the amount of data on which it is trained, more data better the model performs.
For detecting frauds specific to a particular business, you need to input more and more amounts of data into your model. This will train your model in such a way that it detects fraud activities specific to your business perfectly.
Extracting features: Feature extraction basically works on extracting the information of each and every thread associated with a transaction process. These can be the location from where the transaction is made, the identity of the customer, the mode of payments, and the network used for transaction.
- Identity: This parameter is used to check a customer’s email address, mobile number, etc.
- Location: It checks the IP address of the customer and the fraud rates at the customer’s IP address and shipping address.
- Mode of Payment: It checks the cards used for the transaction, the name of the cardholder, cards from different countries, and the rates of fraud of the bank account used.
- Network: It checks for the number of mobile numbers and emails used within a network for the transaction.
Training the Algorithm: Once you have created a fraud detection algorithm, you need to train it by providing customers data so that the fraud detection algorithm learns how to distinguish between ‘fraud’ and ‘genuine’ transactions.
Creating a Model: Once you have trained your fraud detection algorithm on a specific dataset, you are ready with a model that works for detecting ‘fraudulent’ and ‘non-fraudulent’ transactions in your business.
Building Models
Building models is an essential step in predicting the fraud or anomaly in the data sets. We determine how to make that prediction based on previous examples of input and output data. We can further divide the prediction problem into two types of tasks:
1. Classification
2. Regression
Logistic Regression
Regression analysis is a popular, longstanding statistical technique that measures the strength of cause-and-effect relationships in structured data sets. Regression analysis tends to become more sophisticated when applied to fraud detection due to the number of variables and size of the data sets. It can provide value by assessing the predictive power of individual variables or combinations of variables as part of a larger fraud strategy. In this techniques, the authentic transactions are compared with the fraud ones to create an algorithm. This model (algorithm) will predict whether a new transaction is fraudulent or not. For very large merchants these models are specific to their customer base, but usually, general models will apply.
Decision Tree
This is a mature machine learning algorithm family used to automate the creation of rules for classification tasks. Decision Tree algorithms can use for classification or regression predictive modeling problems. They are essentially a set of rules which are trained using examples of fraud that clients are facing. The creation of a tree ignores irrelevant features and does not require extensive normalization of the data. A tree can be inspected and we can understand why a decision was made by following the list of rules triggered by a certain customer. The output of the machine learning algorithm might be a model like the following decision tree. This gives a probability score of fraud based on earlier scenarios.

Random Forest
Random Forest technique uses a combination of multiple decision trees to improve the performance of the classification or regression. It allows us to smooth the error which might exist in a single tree. It increases the overall performance and accuracy of the model while maintaining our ability to interpret the results and provide explainable scores to our users. Random forest runtimes are quite fast, and they are able to deal with unbalanced and missing data. Random Forest weaknesses are that when used for regression they cannot predict beyond the range in the training data and that they may over-fit data sets that are particularly noisy. Of course, the best test of any algorithm is how well it works upon your own data set.
Neural Networks
It is an excellent complement to other techniques and improves with exposure to data. The neural network is a part of cognitive computing technology where the machine mimics how the human brain works and how it observes patterns. The neural networks are completely adaptive; able to learn from patterns of legitimate behavior. These can adapt to the change in the behavior of normal transactions and identify patterns of fraud transactions. The process of the neural networks is extremely fast and can make decisions in real time.
How PayPal uses ML To manage payments
Just like traditional financial institutions, PayPal uses logistic regression for fraud detection. Recently, it has started to turn to more advanced AI tech like deep learning, active learning and transfer learning with their Risk AI journey. As a result, it has been continually achieving 10–20% more accuracy over other traditional ML approaches in real time fraud detection.
PayPal primarily leverages machine learning to enhance its risk management and fraud detection capabilities. From a profitability standpoint, being able to detect fraudulent transactions is imperative for PayPal since payment processing is a low margin business where revenues are split among multiple players: issuing banks, networks, merchant bank, payment gateways, and processors. From a customer engagement and retention standpoint, PayPal must ensure that good customers are able to complete their transactions (no false positives). Going forward, frictionless consumer payment experiences will be key for PayPal to defend its incumbent position in an industry with growing competition.
For the tech stack, PayPal runs one of the most massive hybrid-cloud environments in the world. It hosts multiple technologies in each layer and function. Around 2700 applications are running over 20000 servers with 238 PetaBytes of storage.
They use relational and non-relationship databases like RDBMSs Oracle Parallel Server, MySQL, NoSQL, Couchbase, MongoDB and Cassandra. Besides, for big data and analytics PayPal uses Hadoop, Apache Spark, Elastic Search, Druid and Teradata.
For the frontend, it leverages React, Node.js/kraken framework with Javascript programming. The backend tech stack is primarily based on Java with Springboot framework and REST.
Summary:
As long the modern world is overwhelmed with card-not-present transactions online, the Banking and Retail sectors are under threat and face many fraud cases. Email phishing, payment fraud, identity theft, document forgery, and fake accounts contribute to the high level of criminal attacks on vulnerable users’ data and lead to data breaches. As old rule-based algorithms for fraud detection fade into the past, new top-notch methods based on Machine Learning algorithms for fraud detection and prevention are bringing greater value to businesses with their real-time work, speed, and efficiency.
Further reading:
- https://www.forbes.com/sites/louiscolumbus/2019/08/01/ai-is-predicting-the-future-of-online-fraud-detection/
- https://pegus.digital/how-ai-can-help-combat-fraud/
- https://dzone.com/articles/how-ai-companies-are-gearing-up-to-mitigate-digita
- https://www.netguru.com/blog/fraud-detection-with-machine-learning-banking
